
Multi-Head Attention 架構
「把同一組輸入,用多組不同的 Q、K、V 權重進行注意力計算,最後再把結果合併起來。」
流程步驟如下:
假設我們有輸入向量 $X$,它的維度是 (seq_len,dmodel),例如一個句子裡有 10 個詞,每個詞是 512 維。
1. 將輸入向量投影成多組 Q/K/V:
對每個 Attention 頭 ii,都各自學一組投影矩陣:
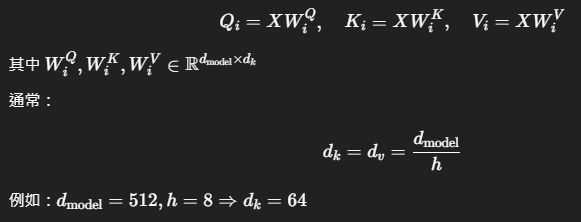
2. 對每一組 Qi,Ki,ViQ_i, K_i, V_i 做 Attention 計算:
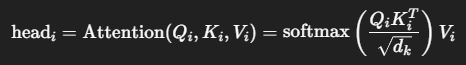
這樣做 h 次,會得到 h 個不同觀點的表示向量。
3. 將所有 head 的結果拼接起來(Concat):
![]()
-
Concat(⋯ ) 的結果維度是 (seq_len,h⋅dk)
-
:再投影回原本的維度
簡單邏輯流程圖解
輸入 X
↓
線性轉換成多組 Q/K/V(8 組)
↓
每組分別做 Attention → head1, head2, …, head8
↓
拼接所有 heads 結果
↓
再線性轉換一次(W^O)
↓
輸出到下一層
範例
假設一句話是:
“The animal didn’t cross the street because it was too tired.”
單一注意力可能難以判斷 “it” 是誰(動物 or 街道),但多頭注意力可能這樣分工:
-
head1:語法關係(主詞、動詞等)
-
head2:語意關係(it → animal)
-
head3:時間性
-
head4:空間性
-
…
所以「多頭注意力」就像是多個專家同時審題,最後彙總各方意見,做出更準確的判斷。